 封面图加载中
封面图加载中
Kafka+zookeeper集群介绍
工作流程图
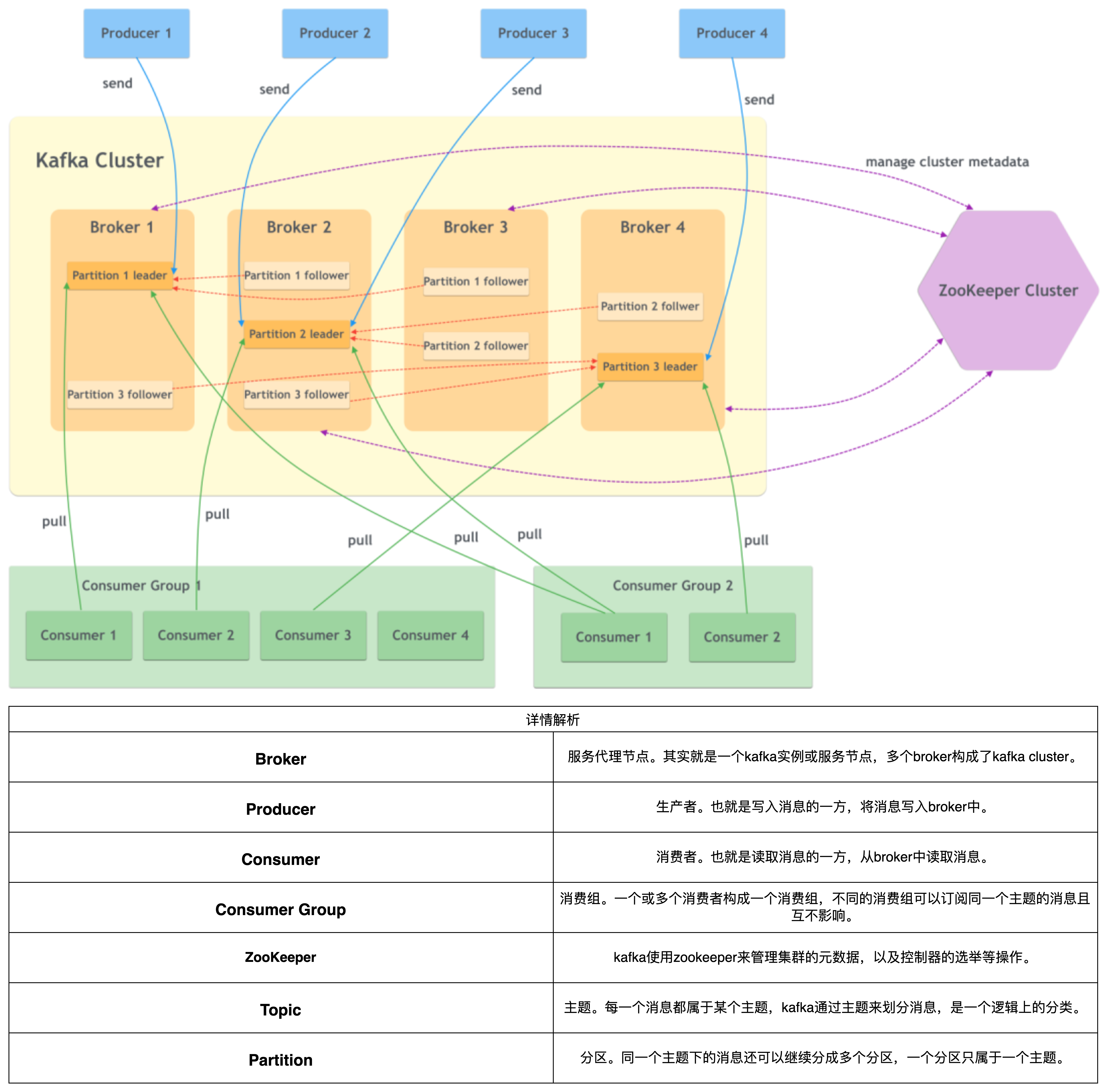
Kafka 和 ZooKeeper 是现代分布式系统中常用的两个组件,它们各自承担着重要的角色,通常在一起使用以实现高效的数据流处理和系统协调。
Kafka 简介
Kafka 是一个分布式流处理平台,专门用于构建实时数据管道和流应用。其主要特点包括:
Broker:Kafka 集群由多个服务器(broker)组成,每个 broker 负责存储和管理消息。
Topic:消息以主题(topic)的形式组织,每个主题可以有多个分区(partition),以实现并发处理。
Partition:每个主题的分区是有序的消息序列,允许负载均衡和扩展。
Replica:为了提高可用性和容错性,分区可以有多个副本(replica),其中一个是主副本(leader)。
Producer 和 Consumer:生产者(producer)向主题发送消息,消费者(consumer)从主题读取消息,支持消费者组以实现负载均衡。
Kafka 的优点
高吞吐量:能够处理大量数据流,适合实时数据处理。
可扩展性:通过增加 broker 数量,轻松应对数据量和消费者数量的增长。
持久性:消息持久化到磁盘,确保数据不丢失。
容错性:通过数据复制提供高可用性。
灵活的消费模式:支持实时和批量处理。
强大的生态系统:包括 Kafka Streams、Kafka Connect 等工具,方便数据处理和集成。
Kafka 的缺点
管理复杂性:集群的管理和监控可能比较复杂。
消息顺序性:只能保证每个分区内的消息顺序,无法保证全局顺序。
延迟:在高负载情况下,消息延迟可能增加。
学习曲线:新手需要一定的时间来理解其概念和最佳实践。
存储成本:持久化大量数据可能增加存储成本。
ZooKeeper 简介
ZooKeeper 是一个开源的分布式协调服务,主要用于管理大型分布式系统中的配置信息、命名、同步和组服务。其主要功能包括:
配置管理:提供集中式的配置管理。
命名服务:提供统一的命名空间。
分布式同步:通过锁机制帮助节点间同步。
组管理:支持动态的组成员管理。
高可用性:采用主从架构,确保系统在节点故障时仍然正常工作。
结合总结
Kafka 和 ZooKeeper 通常结合使用,以实现高效的分布式数据处理和系统协调。Kafka 负责消息的高效传递和处理,而 ZooKeeper 则提供集群管理、配置管理和协调服务。尽管 Kafka 在某些版本中逐渐减少对 ZooKeeper 的依赖(如 Kafka KRaft 模式),但 ZooKeeper 依然在许多场景中发挥着重要作用,尤其是在需要高可靠性和一致性的分布式系统中。通过结合这两者,开发者能够构建出性能优越、可扩展且高可用的分布式应用。
安装环境的前置
yum -y install jave #kafka以及zookeeper是使用的java底层运行,我们需要安装jave
yum -y install supervisor #服务管理器,咱们使用supervisor启动,这样更好管理服务
yum -y install unzip #安装解压包服务部署zookeeper控制集群
PS:这里我用的是自己下载的zip包:zookeeper, 官方下载链接:zookeeper官方
上传zookeeper启动包
部署服务器:
192.168.1.1192.168.1.2192.168.1.3部署位置:
/opt/app
解压zookeeper启动包
unzip zookeeper.zip设置zookeeper配置文件
文件路径:
/opt/app/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper #zookeeper myid集群优先级文件 所在位置
# the port at which the clients will connect
clientPort=2181 #zookeeper启动端口号
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
server.1=192.168.1.1:2188:2888 #集群的IP地址,端口不需要动
server.2=192.168.1.2:2188:2888
server.3=192.168.1.3:2188:2888
#forceSync=no
maxSessionTimeout=300000
zookeeper.connection.timeout.ms=60000dataDir=/data/zookeeper:该路径可自行更改,更改后 myid 需要放入此路径!
设置集群的 myid
部署服务器:
192.168.1.1192.168.1.2192.168.1.3
## 进入到 zookeeper myid集群优先级文件 所在位置
cd /data/zookeeper/
## 生成 myid
echo "1" > myid #在 192.168.1.1 服务器
echo "2" > myid #在 192.168.1.2 服务器
echo "3" > myid #在 192.168.1.3 服务器设置zookeeper启动 ini 文件
部署服务器:
192.168.1.1192.168.1.2192.168.1.3
## 创建zookeeper日志文件目录
mkdir -p /var/log/zookeeper/
## 添加文件
vi /etc/supervisord.d/zookeeper.ini
[program:zookeeper]
command=/opt/app/zookeeper/bin/zkServer.sh start-foreground
process_name=%(program_name)s
numprocs=1
directory=/opt/app/zookeeper
autostart=true
autorestart=true
startsecs=5
startretries=3
stopsignal=QUIT
stopwaitsecs=5
user=root
redirect_stderr=true
stdout_logfile=/var/log/zookeeper/zookeeper_supervisor.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=5
;serverurl=AUTO启动 zookeeper 服务
部署服务器:
192.168.1.1192.168.1.2192.168.1.3
## 启动supervisord服务
systemctl start supervisord
## 设置开机自启动
systemctl enable supervisord
## 启动zookeeper服务
supervisorctl update && supervisorctl start zookeeper
## 检查服务是否正常启动
supervisorctl status zookeeper部署kafka集群
PS:这里我用的是自己下载的zip包:kafka ,官方下载链接:kafka官方
上传kafka启动包
部署服务器:
192.168.1.1192.168.1.2192.168.1.3部署位置:
/opt/app
解压kafka启动包
unzip kafka.zip设置kafka配置文件
文件路径:
/opt/app/kafka/config/server.properties
broker.id=1 #集群的id,集群中的每台服务器都不能一致
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.1.1:9092 #集群当前的的服务器IP地址 192.168.1.1 192.168.1.2 192.168.1.3 如果写了地址解析就一定要写解析的域名
num.network.threads=25
num.io.threads=48
socket.send.buffer.bytes=10240000
socket.receive.buffer.bytes=10240000
socket.request.max.bytes=1048576000
log.dirs=/data/kafka #kafka日志地址
num.partitions=48
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.retention.bytes=10737418240
zookeeper.connect=192.168.1.1:2181,192.168.1.2:2181,192.168.1.3:2181 # zookeeper集群IP地址+端口
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
default.replication.factor=2
message.max.bytes=1024000000
max.partition.fetch.bytes=200000000
log.cleaner.enable=true
log.cleanup.policy=delete
delete.topic.enable=true
auto.create.topics.enable=true设置kafka启动 ini 文件
部署服务器:
192.168.1.1192.168.1.2192.168.1.3
## 创建kafka日志文件目录
mkdir -p /var/log/kafka
## 添加文件
vi /etc/supervisord.d/kaf.ini
[program:kafka]
command=/opt/app/kafka/bin/kafka-server-start.sh /opt/app/kafka/config/server.properties
process_name=%(program_name)s
numprocs=1
directory=/opt/app/kafka
autostart=true
autorestart=true
startsecs=5
startretries=3
stopsignal=QUIT
stopwaitsecs=5
user=root
redirect_stderr=true
stdout_logfile=/var/log/kafka/kafka_supervisor.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=5
;serverurl=AUTO启动 kafka 服务
部署服务器:
192.168.1.1192.168.1.2192.168.1.3
## 启动supervisord服务
systemctl start supervisord
## 设置开机自启动
systemctl enable supervisord
## 启动kafka服务
supervisorctl update && supervisorctl start kafka
## 检查服务是否正常启动
supervisorctl status kafka测试生产和消费
生产主题:
xiaopalu生产地址:
/opt/app/kafka/bin测试生产服务器地址:
192.168.1.1
./kafka-console-producer.sh --broker-list 192.168.1.1:9092 --topic xiaopalu消费主题:
xiaopalu消费地址:
/opt/app/kafka/bin测试生产服务器地址:
192.168.1.3
./kafka-console-consumer.sh --bootstrap-server 192.168.1.3:9092 --topic xiaopalu --from-beginning注意事项
推送数据:
推送数据必须是与kafka配置文件中的IP地址是相同网段才可推送成功!
待补充......